
반응형

-- 본 포스팅은 파이토치로 배우는 자연어 처리 (한빛미디어) 책을 참고해서 작성된 글입니다.
-- 소스코드는 여기
1. NLP에서의 시퀀스
1.1 시퀀스란
- 순서가 있는 항목의 모음
- 순차 데이터
▶ 예시
The book is on the table.
The boos are on the table.위 두개의 문장은 영어에서 다수인지 복수인지에 따라 동사가 달라진다. 이런 문장은 아래와 같이 문장이 길어질 수록 의존성이 더 높아질 수 있다.
The book that I got yesterday is on the table.
The books read by the second=grade children are shelved in the lower rack.
딥러닝에서의 시퀀스 모델링은 숨겨진 '상태 정보(은닉 상태)'를 유지하는 것과 관련이 있다. 시퀀스에 있는 각 항목이 은닉 상태를 업데이트 하고, 시퀀스 표현이라고 불리는 이 은닉상태의 벡터를 시퀀스 모델링 작업에 활용하는 과정을 거친다. 가장 대표적인 시퀀스 신경망 모델은 'RNN(Recurrent nerual network)'이다. 그럼 NLP에서의 시퀀스 모데루 RNN에 대해서 알아보도록 하자.
2. 순환 신경망, RNN (recurrent neural network)
- RNN의 목적은 시퀀스 텐서를 모델링 하는 것
- 입력과 출력을 시퀀스 단위로 처리함
- RNN의 종류는 여러가지가 있지만, 해당 포스팅에서는 엘만RNN에 대해 다룰 것임
- 두개의 RNN 을 활용한 sequence2sequence 다양한 RNN모델이 NLP영역에서 활용되고 있다.
- 같은 파라미터를 활용해서 타임 스텝마다 출력을 계산하고, 이때 은닉 상태의 벡터에 의존해서 시퀀스의 상태를 감지한다.
- RNN의 주 목적은 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산함으로써 시퀀스의 불변성을 학습하는 것이다.
2.1 동작 방식
- 피드 포워드 신경망과는 다르게, 은닉층 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 봬면서 동시에 다시 은닉층 노드의 다음 계산 입력으로 보내는 특징을 가짐
- 즉, 현재 입력 벡터와 이전 은닉 상태 벡터로 현재의 은닉 상태 벡터를 계산함
- 엘만RNN 에서는 은닉벡터가 예측 대상이다.
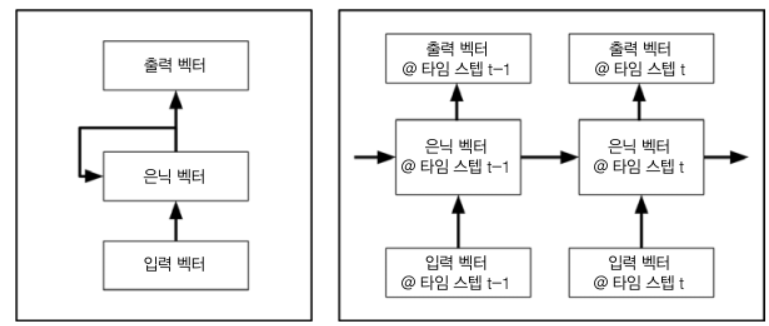
- 구체적인 계산 방식은 아래와 같다

- 은닉-은닉 가중치 행렬을 사용해 이전 은닉 상태 벡터를 매핑
- 입력-은닉 가중치 행렬을 사용해 현재 입력 벡터를 매핑
- 두 개의 값을 더하여 새로운 은닉 벡터를 생성하는 과정을 거친다.
3. RNN 구현하기
- RNN을 활용해서 '성씨 분류'하는 예제를 진행할 예정
- 데이터를 만들어주는Dataset, Vocabulary, Vectorizer class는 이전 포스팅과 동일 (클릭)
- 시퀀스 형태의 인풋 데이터를 활용하는 것이 차이점
▶ column_gather 함수
- 배치 행 인덱스를 순회하면서 x_lengths에 있는 값에 해당하는 인덱스 위치 (즉, 시퀀스의 마지막 인덱스에 있는)의 벡터를 반환하는 함수
def column_gather(y_out, x_lengths):
''' y_out에 있는 각 데이터 포인트에서 마지막 벡터 추출합니다
조금 더 구체적으로 말하면 배치 행 인덱스를 순회하면서
x_lengths에 있는 값에 해당하는 인덱스 위치의 벡터를 반환합니다.
매개변수:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, sequence, feature)
x_lengths (torch.LongTensor, torch.cuda.LongTensor)
shape: (batch,)
반환값:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, feature)
'''
x_lengths = x_lengths.long().detach().cpu().numpy() - 1
out = []
for batch_index, column_index in enumerate(x_lengths):
out.append(y_out[batch_index, column_index])
return torch.stack(out)
▶엘만RNN 함수
- RNNCell을 사용하여 만든 RNN 모델
- 최종값으로 각 타임step에서의 은닉벡터를 반환한다
class ElmanRNN(nn.Module):
""" RNNCell을 사용하여 만든 엘만 RNN """
def __init__(self, input_size, hidden_size, batch_first=False):
"""
매개변수:
input_size (int): 입력 벡터 크기
hidden_size (int): 은닉 상태 벡터 크기
batch_first (bool): 0번째 차원이 배치인지 여부
"""
super(ElmanRNN, self).__init__()
# RNNCell을 사용하여 입력-은닉 가중치 행렬과 은닉-은닉가중치행렬을 만드는 것임
# RNNCell을 호출할때마다 입력벡터와 은닉행렬을 받는다
self.rnn_cell = nn.RNNCell(input_size, hidden_size)
self.batch_first = batch_first
self.hidden_size = hidden_size
def _initial_hidden(self, batch_size):
return torch.zeros((batch_size, self.hidden_size))
def forward(self, x_in, initial_hidden=None):
# 입력텐서를 순회하면서 타입스텝마다 은닉상태 벡터를 계산해주는 forward메서드
""" ElmanRNN의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
If self.batch_first: x_in.shape = (batch_size, seq_size, feat_size)
Else: x_in.shape = (seq_size, batch_size, feat_size)
initial_hidden (torch.Tensor): RNN의 초기 은닉 상태
반환값:
hiddens (torch.Tensor): 각 타임 스텝에서 RNN 출력
If self.batch_first:
hiddens.shape = (batch_size, seq_size, hidden_size)
Else: hiddens.shape = (seq_size, batch_size, hidden_size)
"""
# batch_first가 True이면출력은닉상태의 배치 차원을 0번째로 바꿈(?)
if self.batch_first:
batch_size, seq_size, feat_size = x_in.size()
x_in = x_in.permute(1, 0, 2)
else:
seq_size, batch_size, feat_size = x_in.size()
hiddens = []
if initial_hidden is None:
initial_hidden = self._initial_hidden(batch_size)
initial_hidden = initial_hidden.to(x_in.device)
hidden_t = initial_hidden
for t in range(seq_size):
hidden_t = self.rnn_cell(x_in[t], hidden_t)
hiddens.append(hidden_t)
hiddens = torch.stack(hiddens)
if self.batch_first:
hiddens = hiddens.permute(1, 0, 2)
return hiddens▶훈련에서 사용할 SurnameClassifier 함수
- RNN과 Linear층으로 나뉨
- RNN층에서 시퀀스의 벡터 표현 (히든벡터)를 계산해주고 성씨의 마지막 문자에 해당하는 벡터를 추출해주는 역할을 수행 (성씨의 마지막 문자에 해당하는 벡터란, 최종 벡터를 말한다.)
- 최종벡터가 전체시퀀스 입력을 거쳐 전달된 결과물인 요약벡터라고 할 수있다.
- Linear층에서 요약벡터를 활용하여 예측벡터를 계산한다.
# RNN층, Linear 층으로 나뉨
class SurnameClassifier(nn.Module):
""" RNN으로 특성을 추출하고 MLP로 분류하는 분류 모델 """
def __init__(self, embedding_size, num_embeddings, num_classes,
rnn_hidden_size, batch_first=True, padding_idx=0):
"""
매개변수:
embedding_size (int): 문자 임베딩의 크기
num_embeddings (int): 임베딩할 문자 개수
num_classes (int): 예측 벡터의 크기
노트: 국적 개수
rnn_hidden_size (int): RNN의 은닉 상태 크기
batch_first (bool): 입력 텐서의 0번째 차원이 배치인지 시퀀스인지 나타내는 플래그
padding_idx (int): 텐서 패딩을 위한 인덱스;
torch.nn.Embedding을 참고하세요
"""
super(SurnameClassifier, self).__init__()
#먼저 임베딩층을 사용하여 정수를 임베딩해줌
self.emb = nn.Embedding(num_embeddings=num_embeddings,
embedding_dim=embedding_size,
padding_idx=padding_idx)
# 그 다음 RNN층으로 시퀀스의 벡터표현을 계산해줌
# 이 벡터는 성씨에 있는 각 문자에 대한 은닉상태를 나타냄
# 성씨의 마지막 문자에 해당하는 벡터를 추출 (최종벡터)
# 이 최종벡터가 전체 시퀀스 입력을 거쳐 전달된 결과물이라고 할 수있음 (성씨를 요약한 벡터)
self.rnn = ElmanRNN(input_size=embedding_size,
hidden_size=rnn_hidden_size,
batch_first=batch_first)
# 요약벡터를 linear 층으로 전달하여 예측벡터 계산
# 예측벡터를 사용하여 softmax함수에 적용하거나, 훈련 손실을 계산하여 성씨에 대한 확률 분포를 만든다.
self.fc1 = nn.Linear(in_features=rnn_hidden_size,
out_features=rnn_hidden_size)
self.fc2 = nn.Linear(in_features=rnn_hidden_size,
out_features=num_classes)
# 시퀀스의 길이 x_length가 필요
# 시퀀스의 길이는 gather_column()함수를 사용하여 텐서에서 시퀀스마다 마지막 벡터를 추출하여 반환
def forward(self, x_in, x_lengths=None, apply_softmax=False):
""" 분류기의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
x_in.shape는 (batch, input_dim)입니다
x_lengths (torch.Tensor): 배치에 있는 각 시퀀스의 길이
시퀀스의 마지막 벡터를 찾는데 사용합니다
apply_softmax (bool): 소프트맥스 활성화 함수를 위한 플래그
크로스-엔트로피 손실을 사용하려면 False로 지정합니다
반환값:
결과 텐서. tensor.shape는 (batch, output_dim)입니다.
"""
x_embedded = self.emb(x_in)
y_out = self.rnn(x_embedded)
if x_lengths is not None:
# column_gather : 조금 더 구체적으로 말하면 배치 행 인덱스를 순회하면서
# x_lengths에 있는 값에 해당하는(시퀀스의 마지막 인덱스에 있는) 인덱스 위치의 벡터를 반환하는 함수
y_out = column_gather(y_out, x_lengths)
else:
y_out = y_out[:, -1, :]
y_out = F.relu(self.fc1(F.dropout(y_out, 0.5)))
y_out = self.fc2(F.dropout(y_out, 0.5))
if apply_softmax:
y_out = F.softmax(y_out, dim=1)
return y_out
반응형
'AI study > 자연어 처리 (NLP)' 카테고리의 다른 글
| [NLP] seq2seq로 번역기 구현하기 (feat.딥러닝을 이용한 자연어 처리 입문) (0) | 2021.08.06 |
|---|---|
| [NLP] 자연어 처리를 위한 시퀀스 모델링 (Attention, 어텐션 메커니즘) (0) | 2021.08.06 |
| [NLP] Pytorch를 활용하여 CBOW 임베딩 학습하기 (2)모델 훈련 (0) | 2021.07.29 |
| [NLP] Pytorch를 활용하여 CBOW 임베딩 학습하기 (1)데이터셋 생성 (0) | 2021.07.29 |
| [NLP] 단어 임베딩 (Embedding) (2) | 2021.07.27 |